Resource
Evaluating the Accuracy of the Copyleaks AI Detector
A Step-by-Step Methodology
Test date: May 25, 2024
Model tested: V5
We believe it is more important than ever to be fully transparent about the AI Detector’s accuracy, the rates of false positives and false negatives, areas for improvement, and more to ensure responsible use and adoption. This comprehensive analysis aims to ensure full transparency around our AI Detector’s V5 model testing methodology.
The Copyleaks Data Science and QA teams independently performed testing to ensure unbiased and accurate results. Testing data differed from training data and contained no content previously submitted to the AI Detector for AI detection.
Testing data consisted of human-written text sourced from verified datasets and AI-generated text from various AI models. The test was performed with the Copyleaks API.
Metrics include overall accuracy based on the rate of correct and incorrect text identification, in addition to ROC-AUC (Receiver Operating Characteristic – Area Under the Curve), which examines true positive rates (TPR) and false positive rates (FPR). Additional metrics include F1 score, true negative rate (TNR), accuracy, and confusion matrices.
Testing verifies that the AI Detector displays a high detection accuracy for distinguishing between human-written and AI-generated text while maintaining a low false positive rate.
Evaluation Process
Using a dual-department system, we have designed our evaluation process to ensure top-level quality, standards, and reliability. We have two independent departments evaluating the model: the data science and the QA teams. Each department works independently with its evaluation data and tools and does not have access to the other’s evaluation process. This separation ensures the evaluation results are unbiased, objective, and accurate while capturing all possible dimensions of our model’s performance. Also, it is essential to note that the testing data is separated from the training data, and we only test our models on new data that they haven’t seen in the past.
Methodology
Copyleaks’ QA and Data Science teams have independently gathered a variety of testing datasets. Each testing dataset consists of a finite number of texts. The expected label—a marker indicating whether a specific text was written by a human or by AI—of each dataset is determined based on the source of the data. Human texts were collected from texts published before the rise of modern generative AI systems or later on by other trusted sources that were verified again by the team. AI-generated texts were generated using a variety of generative AI models and techniques.
The tests were executed against the Copyleaks API. We checked whether the API’s output was correct for each text based on the target label, and then aggregated the scores to calculate the confusion matrix.
Results: Data Science Team
The Data Science team conducted the following independent test:
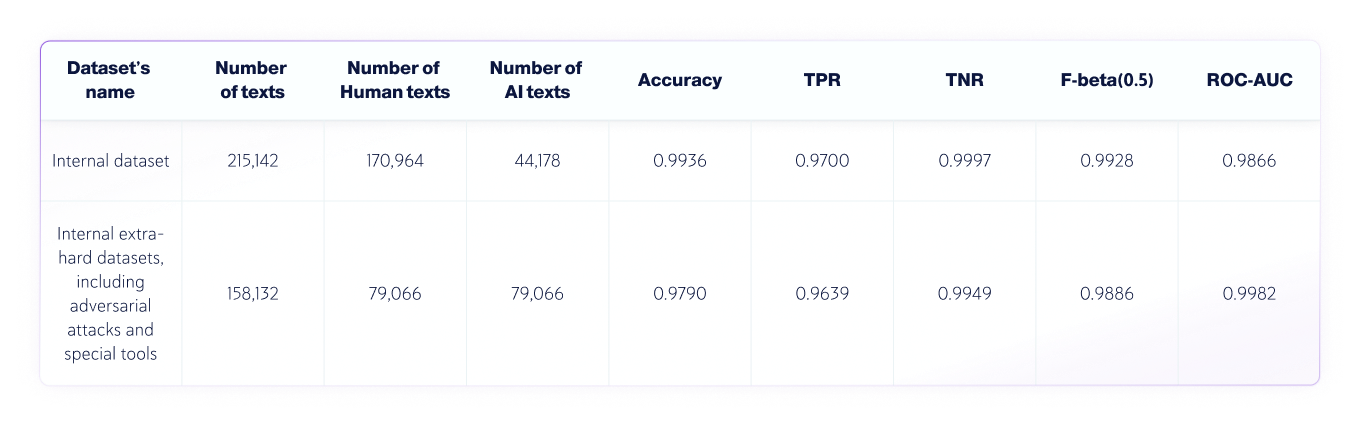
- The language of the texts was English, and 250,030 human-written texts and 123,244 AI-generated texts from various LLMs were tested in total.
- Text lengths vary, but the datasets contain only texts with lengths larger than 350 characters—the minimum our product accepts.
Evaluation Metrics
The metrics that are used in this text classification task are:
1. Confusion matrix: A table that shows the TP (true positives), FP (false positives), TN (true negatives) and FN (false negatives).
2. Accuracy: the proportion of true results (both true positives and true negatives) among the total number of texts that were checked.
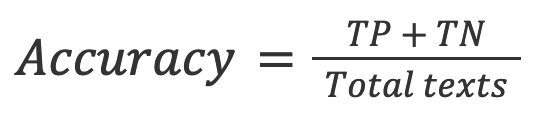
3. TNR: The proportion of the accurate negative predictions in all the negative predictions.
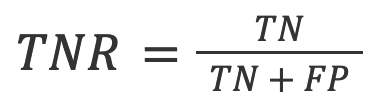
In the context of AI detection, TNR is the model’s accuracy on human texts.
4. TPR (also known as Recall): The proportion of true positive results in all the actual predictions.
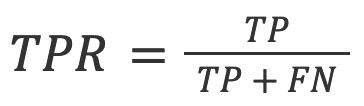
In the context of AI detection, TPR is the model’s accuracy on AI-generated texts.
5. F-beta Score: The weighted harmonic mean between precision and recall, favoring precision more (as we want to favor a lower False Positive Rate).
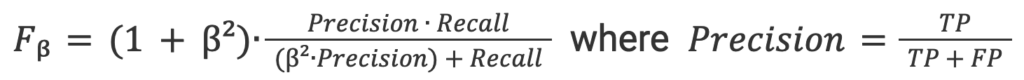
6. ROC-AUC: Evaluation of the trade-off between TPR and FPR.
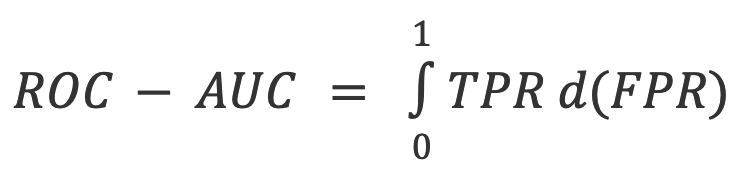
Combined AI and Human Datasets
Results: QA Team
The QA team conducted the following independent test:
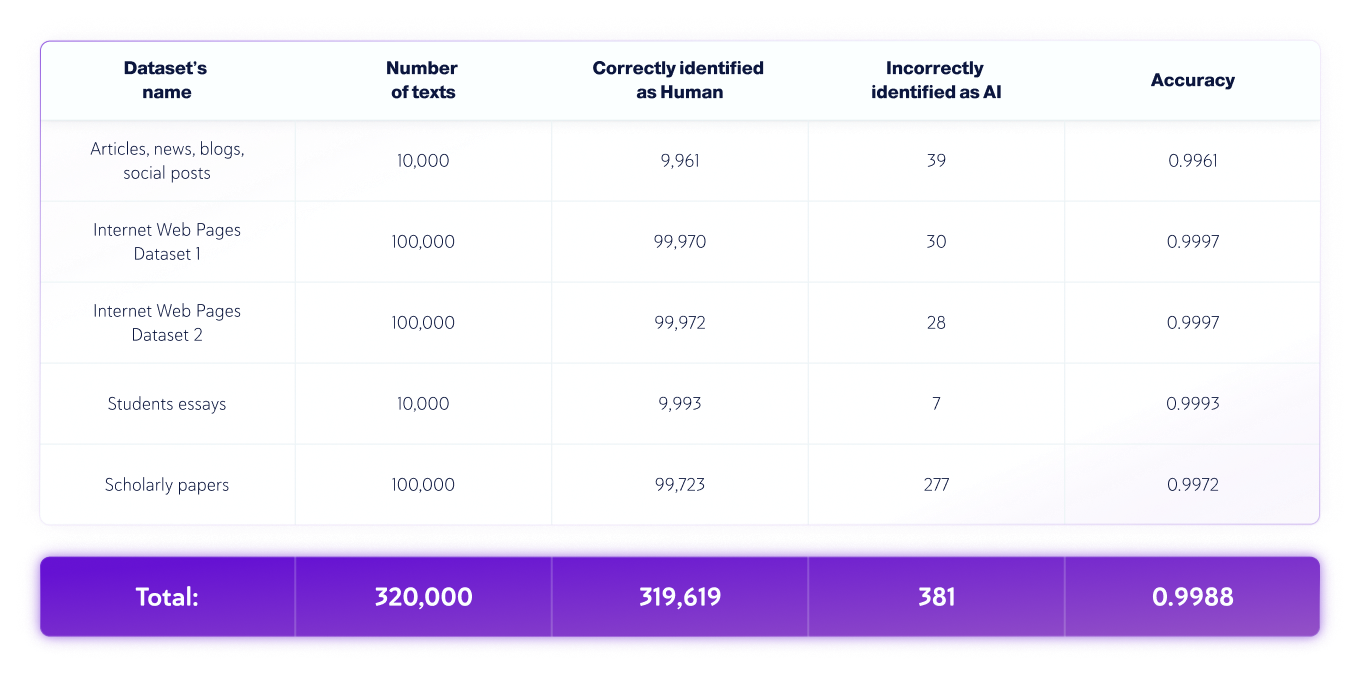
- The language of the text was English, and 320,000 human-written texts and 172,500 AI-generated texts from various LLMs were tested in total.
- Text lengths vary, but the datasets contain only texts with lengths larger than 350 characters—the minimum our product accepts.
Human-Only Datasets
AI-Only Datasets
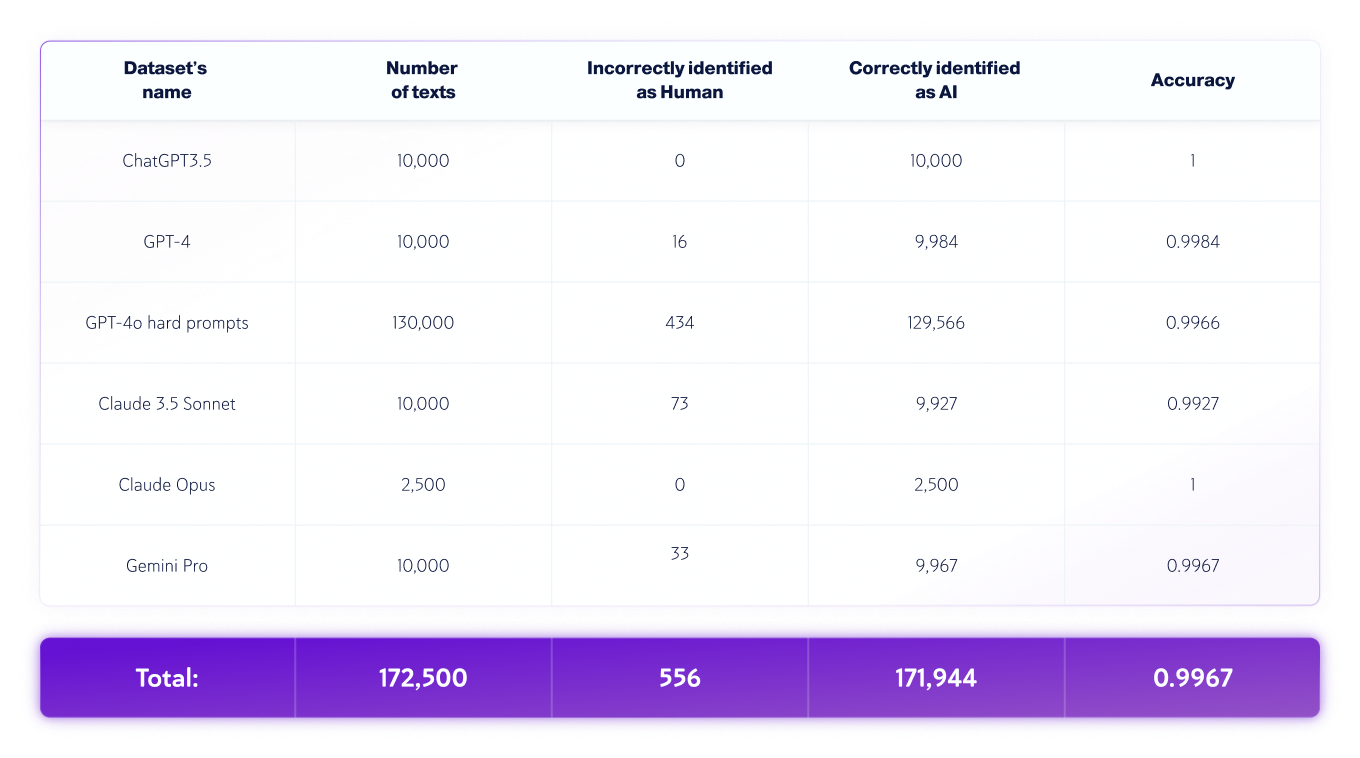
*Model versions may change over time. Texts were generated using one of the available versions of the above generative AI models.
Human and AI Text Error Analysis
During the evaluation process, we identify and analyze mistakes made by the model and output a detailed report that will enable the data science team to correct the underlying causes of these mistakes. This is done without exposing the errors themselves to the data science team. All errors are systematically logged and categorized based on their character and nature in a “root cause analysis process,” which aims to understand the underlying causes and identify repeated patterns. This process is always ongoing, ensuring the improvement and adaptability of our model over time.
One example of such a test is our analysis of internet data from 2013 – 2024 using our V4 model. We sampled 1M texts from each year, starting in 2013, using any false positives detected from 2013-2020, before the release of AI systems, to help improve the model further.
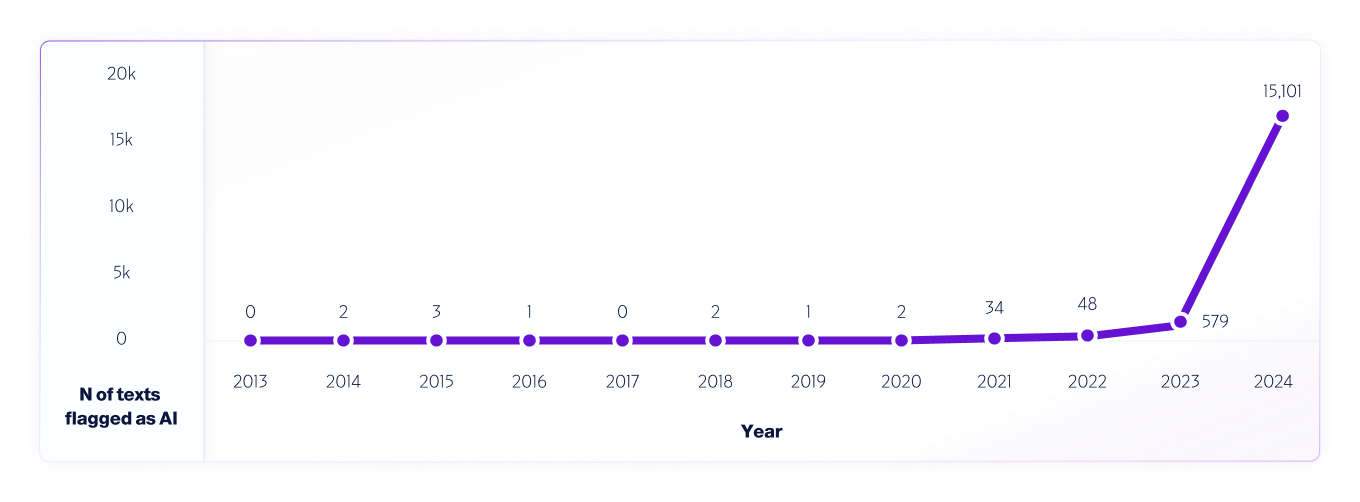
Similar to how researchers worldwide have and continue to test different AI detector platforms to gauge their capabilities and limitations, we fully encourage our users to conduct real-world testing. Ultimately, as new models are released, we will continue to share the testing methodologies, accuracy, and other important considerations to be aware of.